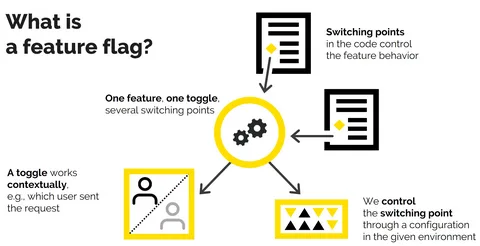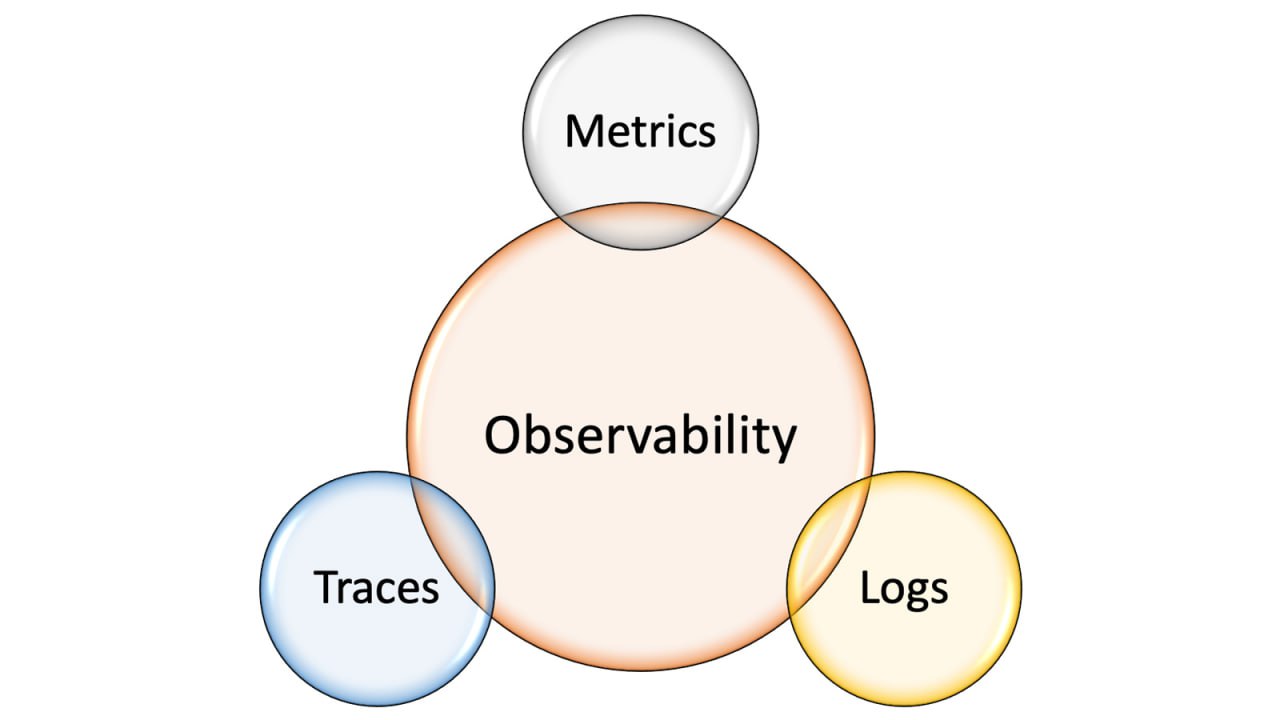
Modern microservice architectures multiply failure modes by design. As services split into smaller units, visibility becomes harder without intentional observability. Teams need to understand how requests traverse boundaries, where latency accumulates, and how partial failures propagate. Observability connects metrics, logs, and traces to explain system behavior under real load, enabling faster diagnosis and safer iteration.
Signals that Matter
Golden signals such as latency, errors, traffic, and saturation highlight user impact. High-cardinality labels reveal edge cases that averages hide. Sampling strategies balance cost with insight during spikes.
Tooling and Process
Consistent instrumentation, trace propagation, and structured logging standardize visibility across teams. Runbooks and alert thresholds aligned to service objectives reduce noise and shorten recovery time.
Continuous Improvement
Post-incident reviews refine dashboards and alerts. Over time, teams evolve observability as products and traffic patterns change.